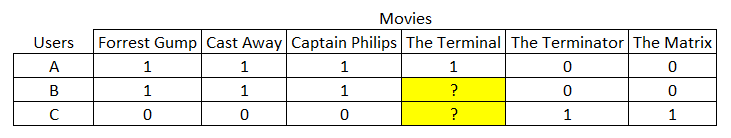Write your Answer here:__
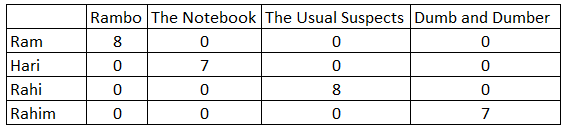
7.1) The base line user-user model "algo_knn_user" had a slightly lower RMSE than the base line item-item model "algo_knn_item", which were 0.9925 and 0.9964 respectively.
The prediction for userId = 4 and movieId = 10 were 3.62 and 4.42 respectively, so for this particular prediction, the user-user model predicted a rating closer to the actual rating of 4.
Also, the item-item model seems to over-predict while the user-user model under-predicts.
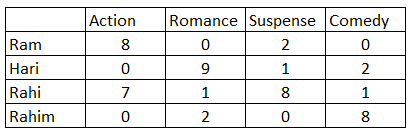
7.2) The baseline models compared to the tuned models have a greater RMSE. In addition, the baseline user-user model predicted a rating (3.62) which was closer to the actual rating than the tuned model which predicted a rating of 3.58. On the other hand, the item-item models behaved the opposite as the tuned model was closer to the actual rating than the baseline model.
7.3) The difference between the matrix faxtorization model and the collaborative filtering models is that the matrix factorization model focuses on the user's past behavior by converting the latent features, such as genre, of the movie the user rates, where as collaborative filtering models are developed based on related users or related items and not the user directly.
The respective RMSE values for the algorithms:
algo_knn_user: 0.9925
similarity_algo_optimized_user: 0.9871
algo_knn_item: 0.9964
similarity_algo_optimized_item: 0.9495
algo_svd: 0.9023
svd_algo_optimized: 0.8955
The precision and recall for all models is shown in Question 6. The precision is the highest for the baseline user-user model with k = 5. The precision is the lowest with the baseline item-item model with k=10. The recall is lowest with the baseline item-item model with k=5. The recall is highest with the baseline user-user model with k=10.
7.4) There was no improvement from the tuned or SVD models as the RMSE and precision continued to decrease with each new algorithm. Eventhough some of the tuned models and SVD models performed better for the specific userId=4, the baseline algorithms perform better on the entire dataset.